Optimizing DPD Algorithm with ARM NEON SIMD
Accelerating Digital Predistortion Performance through NEON Register Optimization
By Myung Guk Lee in Technical Projects
April 29, 2024
Project Overview
This project focused on significantly improving the performance of Digital Predistortion (DPD) algorithm implementation through ARM NEON SIMD optimization. The optimization resulted in substantial performance gains by leveraging parallel processing capabilities of ARM architecture.
Technical Background
Digital Predistortion (DPD)
Digital Predistortion is a crucial technique in modern wireless communication systems that compensates for power amplifier (PA) nonlinearities. The process works by:
- Pre-analyzing the PA’s nonlinear characteristics
- Applying inverse distortion to the input signal
- Achieving linear output after PA processing
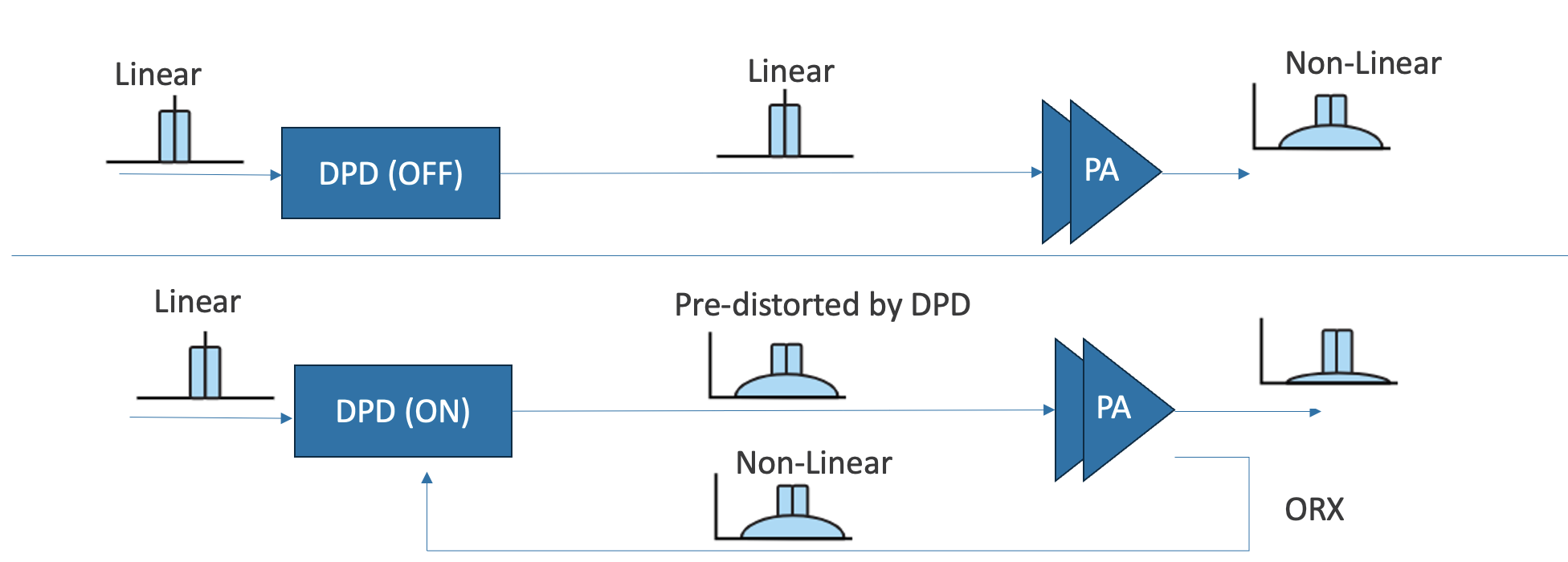 Figure 1: Digital Predistortion working principle showing signal transformation stages
Figure 1: Digital Predistortion working principle showing signal transformation stages
ARM NEON Architecture
NEON is ARM’s advanced SIMD (Single Instruction Multiple Data) architecture extension, designed for high-performance computing applications. Key features include:
- 32 dedicated 128-bit SIMD registers
- Parallel processing capabilities
- Support for both integer and floating-point operations
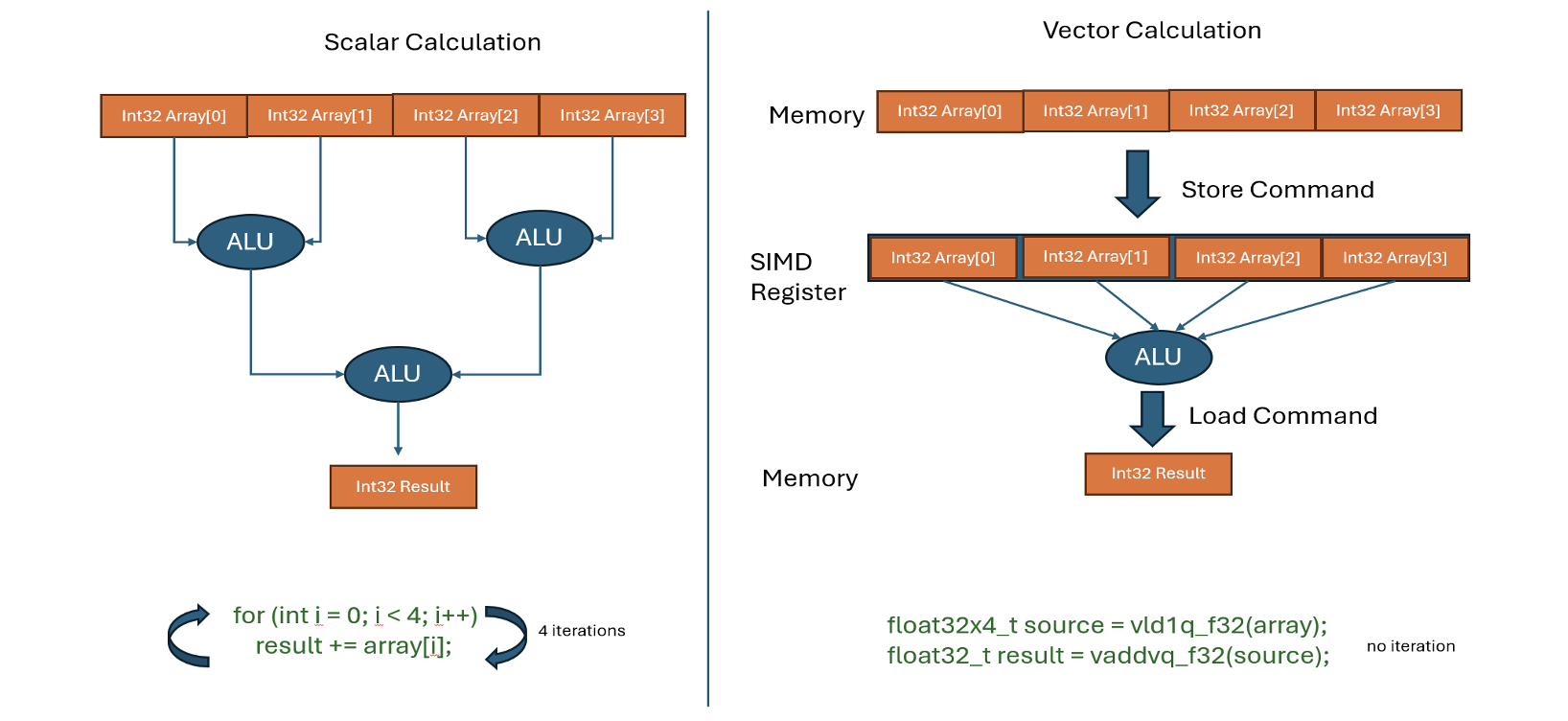 Figure 2: NEON SIMD parallel processing visualization
Figure 2: NEON SIMD parallel processing visualization
Optimization Strategy
1. Memory Alignment and Data Structure Optimization
To maximize NEON register utilization, careful attention was paid to data alignment and structure:
- Memory Alignment: Ensured 128-bit alignment for optimal NEON register loading
- Complex Data Handling: Separated real and imaginary components for efficient SIMD processing
- Contiguous Memory Layout: Optimized data placement for vectorized operations
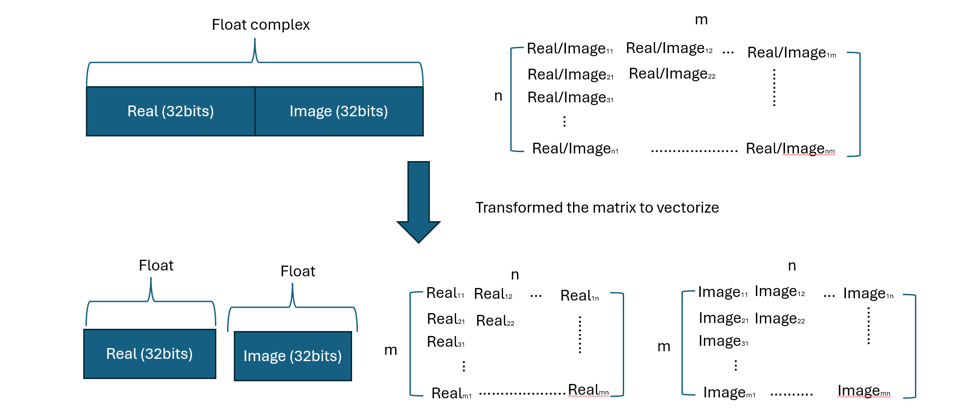 Figure 3: Complex data separation and alignment strategy
Figure 3: Complex data separation and alignment strategy
2. Advanced Loop Optimization
Implemented sophisticated loop optimization techniques:
- Loop Unrolling: Reduced branch predictions and improved instruction pipeline efficiency
- Loop Unwinding: Maximized register utilization and reduced memory access overhead
- Register Allocation: Optimized temporary result storage in NEON registers
 Figure 4: Loop unrolling and unwinding implementation
Figure 4: Loop unrolling and unwinding implementation
3. Matrix Operation Enhancement
Developed an optimized matrix multiplication approach using 4x4 submatrices:
- SIMD Parallelization: Processed multiple elements simultaneously
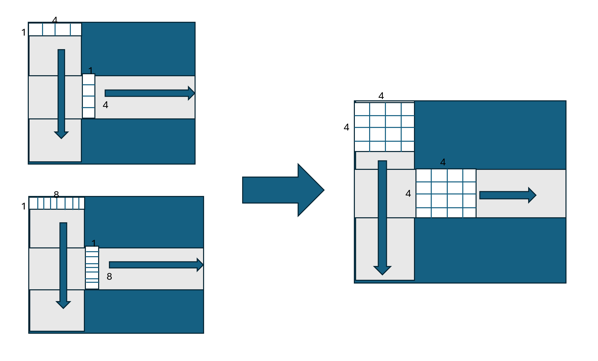 Figure 5: 4x4 submatrix multiplication optimization
Figure 5: 4x4 submatrix multiplication optimization
Performance Results
The optimization efforts resulted in:
- Significant reduction in processing time
- Improved throughput for real-time applications
- Better resource utilization
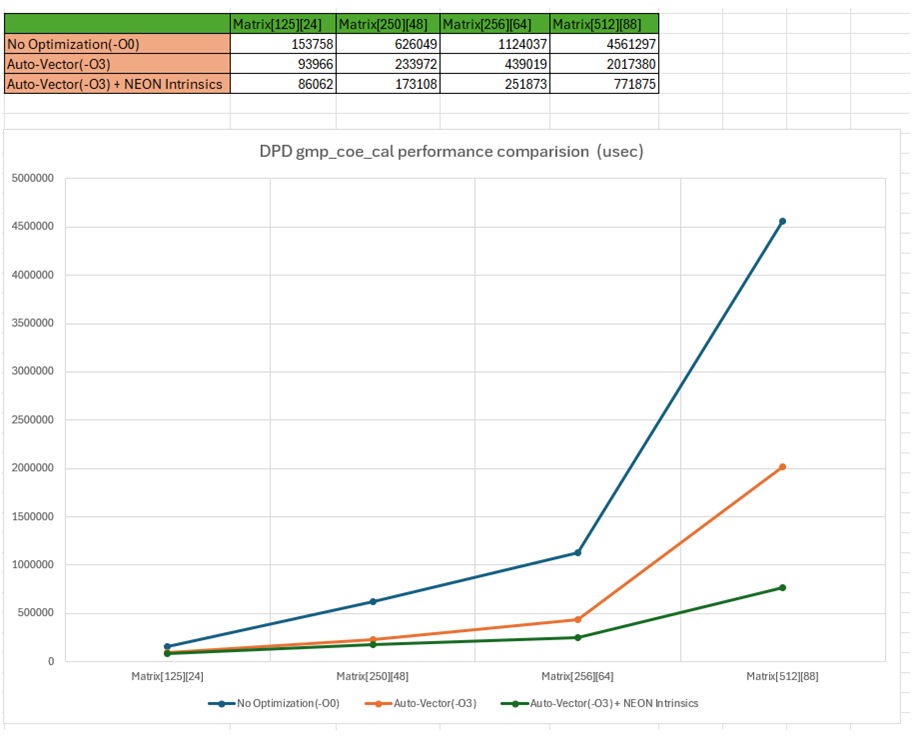 Figure 6: Performance results showing the improvement in processing time and throughput
Figure 6: Performance results showing the improvement in processing time and throughput
- Posted on:
- April 29, 2024
- Length:
- 2 minute read, 299 words
- Categories:
- Technical Projects
- Series:
- Performance Optimization
- See Also: